20250209 모각코 활동 5회차
오늘의 목표 : 기계학습 구현
선형회귀 모델과 트리 모델
필요한 라이브러리 불러오기
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
데이터 불러오기
# 데이터 다운로드
wine = pd.read_csv('https://bit.ly/wine_csv_data')
# 데이터 구조 확인
print(wine.head()) # 처음 5개의 샘플
print(wine.info()) # 데이터프레임의 각 열의 데이터 타입과 누락된 데이터 확인
print(wine.describe()) # 통계 ( 평균, 표준편차, 최소, 최대, 중간값, 1사분위수, 3사분위수 )
alcohol sugar pH class
0 9.4 1.9 3.51 0.0
1 9.8 2.6 3.20 0.0
2 9.8 2.3 3.26 0.0
3 9.8 1.9 3.16 0.0
4 9.4 1.9 3.51 0.0
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6497 entries, 0 to 6496
Data columns (total 4 columns):
Column Non-Null Count Dtype
0 alcohol 6497 non-null float64
1 sugar 6497 non-null float64
2 pH 6497 non-null float64
3 class 6497 non-null float64
dtypes: float64(4)
memory usage: 203.2 KB
None
alcohol sugar pH class
count 6497.000000 6497.000000 6497.000000 6497.000000
mean 10.491801 5.443235 3.218501 0.753886
std 1.192712 4.757804 0.160787 0.430779
min 8.000000 0.600000 2.720000 0.000000
25% 9.500000 1.800000 3.110000 1.000000
50% 10.300000 3.000000 3.210000 1.000000
75% 11.300000 8.100000 3.320000 1.000000
max 14.900000 65.800000 4.010000 1.000000
# 판다스 데이터 프레임 -> 넘파이 배열
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
# 데이터 나누기
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
# 나눈 데이터 형태 확인
print(train_input.shape, test_input.shape)
(5197, 3) (1300, 3)
# 데이터 전처리
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
로지스틱 회귀 모델 훈련
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
print(lr.coef_, lr.intercept_) # 로지스틱 회귀가 학습한 계수와 절편
0.7808350971714451 0.7776923076923077 0.51268071 1.67335441 -0.68775646 [1.81773456]`
트리 모델 훈련
dt = DecisionTreeClassifier(random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
0.996921300750433
0.8592307692307692
# 훈련 결과 시각화
plt.figure(figsize=(10,7))
plot_tree(dt)
plt.show()
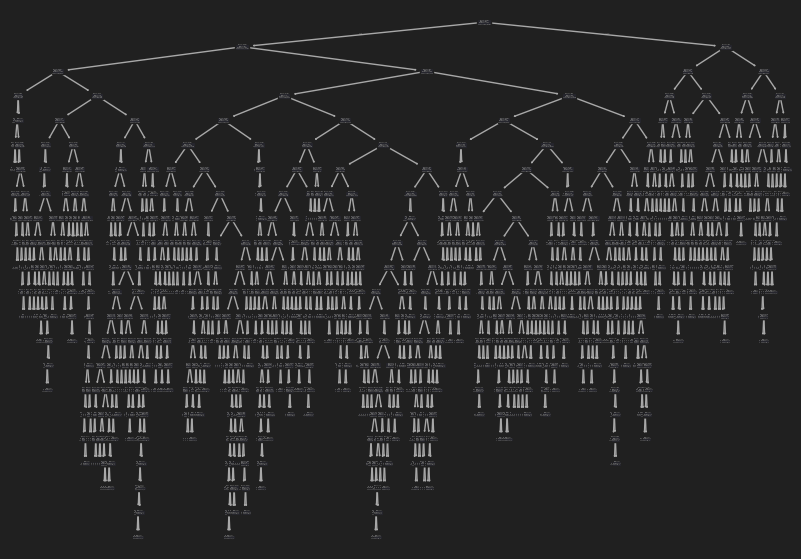
# 자세히 살펴보기
plt.figure(figsize=(10,7))
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
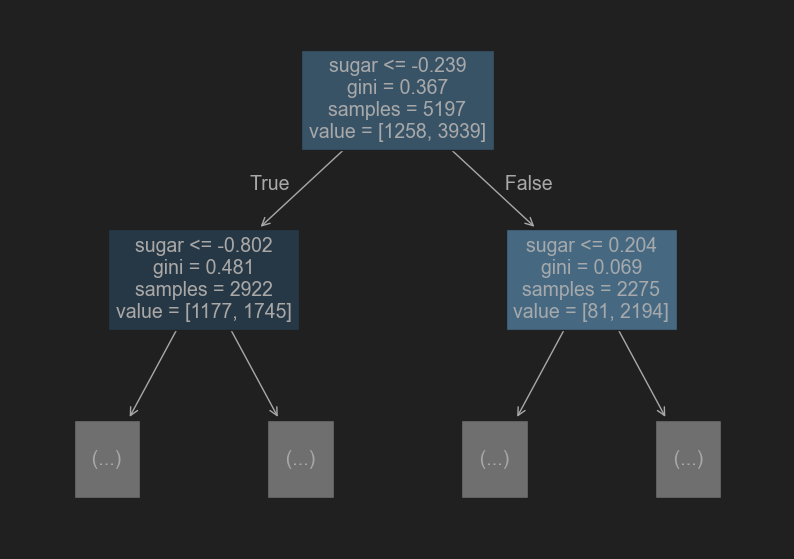
# 가지치기
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
0.8454877814123533
0.8415384615384616
# 가지치고 난 뒤의 훈련 시각화
plt.figure(figsize=(20,15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
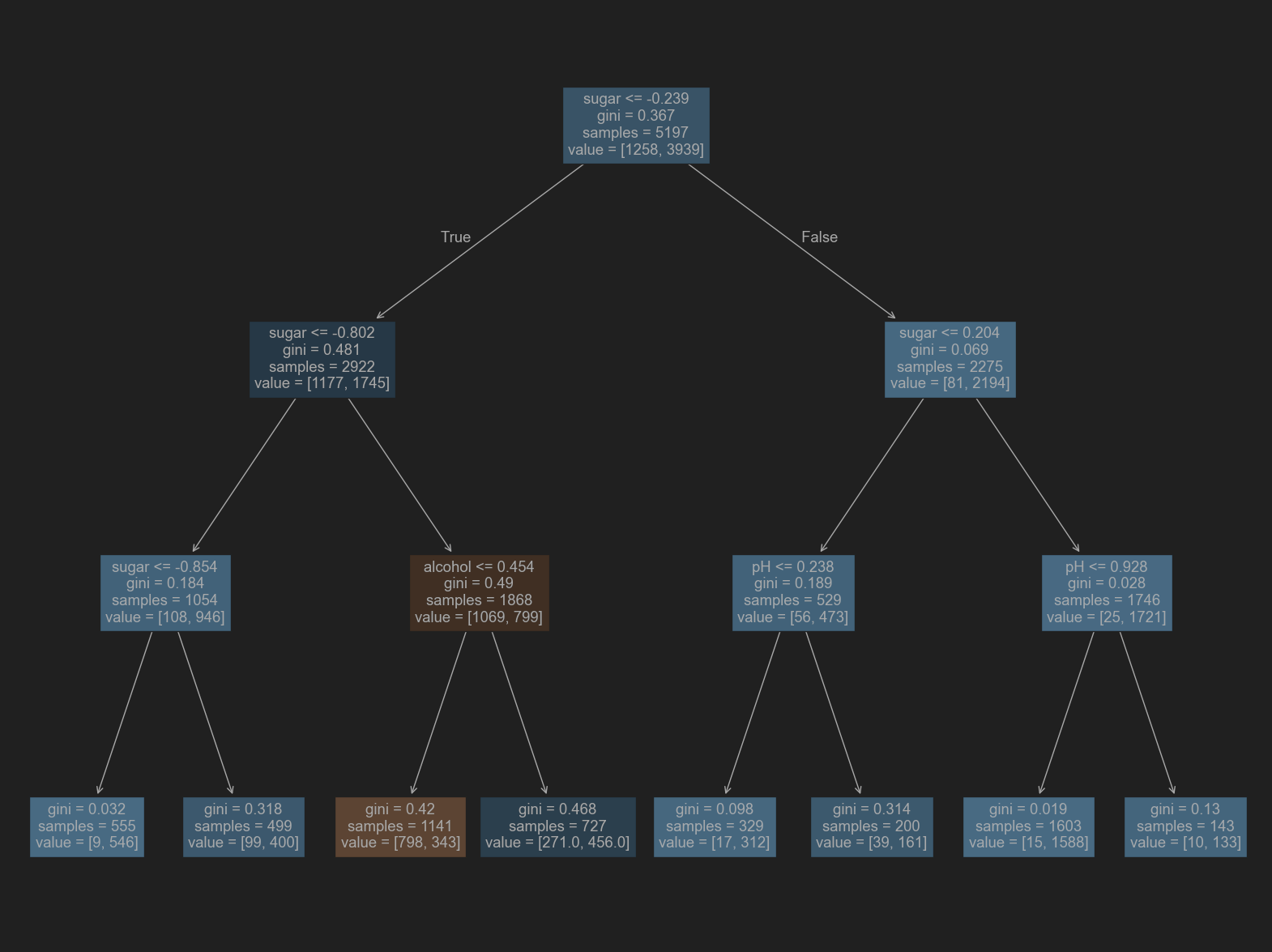
# 전처리 하기 전의 데이터들로 다시 훈련해보기 -> 결과는 같을 것.
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_input, train_target)
print(dt.score(train_input, train_target))
print(dt.score(test_input, test_target))
0.8454877814123533
0.8415384615384616
# 시각화 -> 데이터를 전처리 하고 난 뒤에 훈련 한 것과 같은 트리를 갖지만, 특성값을 표준점수로 바꾸지 않았기 때문에 이해하기 더욱 쉬움.
plt.figure(figsize=(20,15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
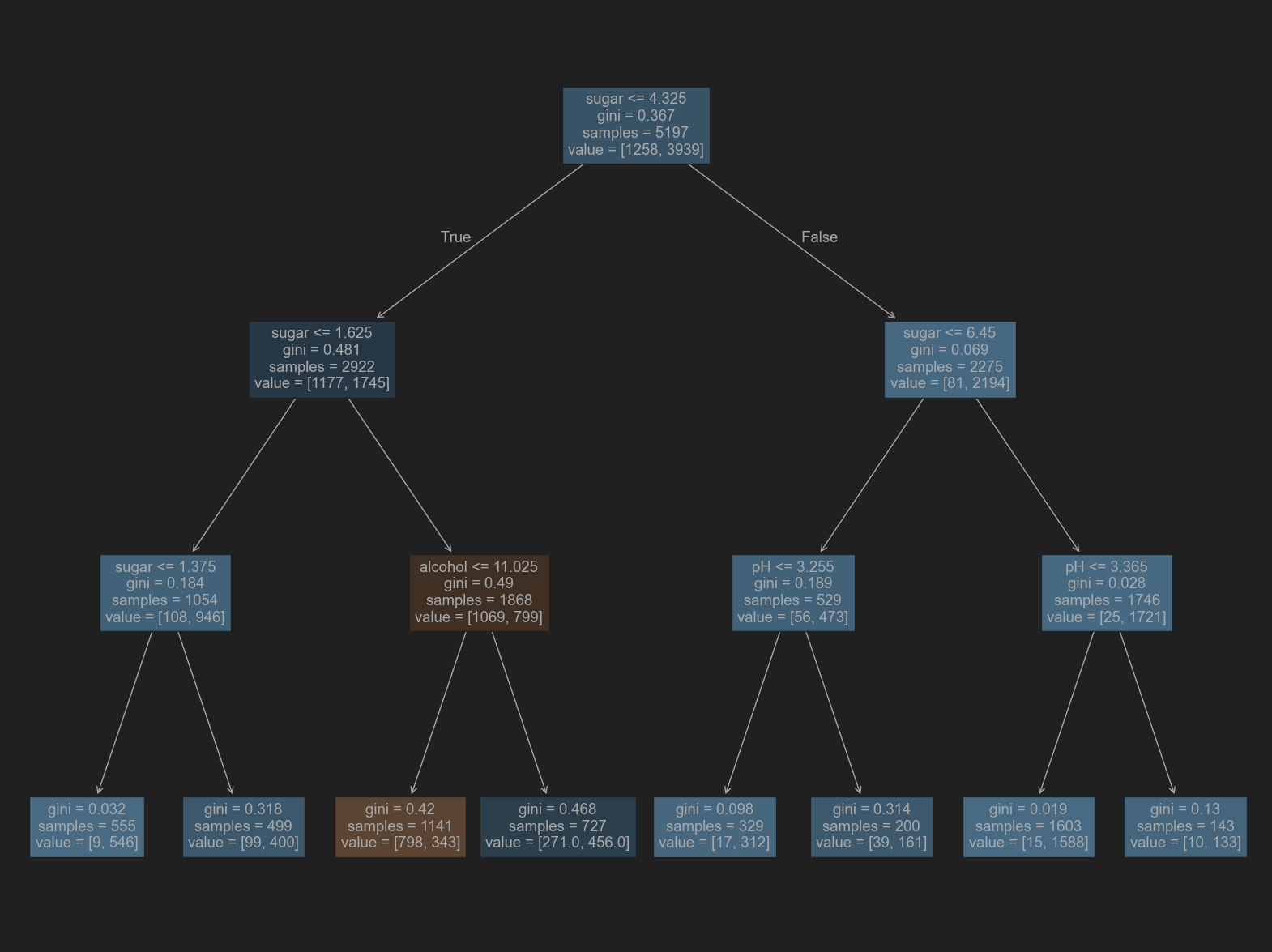
# 특성 중요도
print(dt.feature_importances_)
[0.12345626 0.86862934 0.0079144 ]